Why Stable Diffusion is a big deal? It proves that AI can create

By combining an enormous amount of data with an overload of computing power, AI models are already helping thousands of organisations to automate repetitive tasks and gain useful insights.


But surely, there's no more AI can do for us, right?
Think again! In the summer of 2022, a revolutionary AI model took the internet by storm. Following in the footsteps of models like Dall-E, Stable Diffusion can create artwork, images and videos (almost) from scratch.
Both Dall-E and Stable Diffusion can generate unique material, based on any textual input (or images). But what's so groundbreaking about Stable Diffusion? How could it transform businesses like yours? And why is everyone talking about this? Let's find out.
Things you can do with Stable Diffusion
Stable Diffusion is primarily used to generate detailed images guided by text descriptions (called prompts). Unlike Dall-E, Stable Diffusion is free and open-source – no need to worry about private companies spying on your images.
The model can interpret the prompt and will create original images that closely resemble it.
Below, you can see how different prompts impact the result.




In addition to the text-to-image interpretation, Stable Diffusion also supports inpainting, outpainting and img2img transformations.
Inpainting
By masking a part of the image, Stable Diffusion can be applied to the masked area alone.




You may find yourself wondering: will Photoshop still be useful? For sure! Both tools perfectly complement each other. You can even use the Stability Photoshop plug-in to integrate Stable Diffusion's features into the interface of Photoshop.
Outpainting
Outpainting allows you to extend the original image beyond its boundaries.



Ever wondered what the house of the Girl with a Pearl Earring looked like? Just let AI imagine it for you.


Img2img
Instead of generating a completely random image, the text prompt can also be influenced with a starting image. As you can see in the images below, the colours of the resulting image are very similar to the original.


Nice gimmick, but what’s the use?
At this point, Stable Diffusion may seem like a fun way to spend your Sunday, but don't be fooled: this technology unlocks a huge potential for new and existing businesses. Besides creating artwork (and winning art competitions), AI models like this allow us to bring more ‘mixed reality’ applications to the market. Essentially, that means combining something real with something that isn’t there (yet).
Think about shopping for new clothes: what if you could let an image of yourself try on coats or shirts in a virtual shop?
By combining (or chaining) multiple AI’s, it's possible to automatically detect the original clothing on an image and replace these clothes – all in a matter of seconds and without any manual intervention.



You could also play with interior design. Would you rather see your home in a Scandinavian style? Or maybe you're more of a maximalist?




AI bridges the gap between finding inspiration and seeing it right in front of you.
Professionals might see these innovations as a threat – but quite the opposite is true. AI will only expand the set of tools already available.
Fine-tuning Stable Diffusion
Training Stable Diffusion yourself is not something you can easily do, as the total training costs around $600k. However, some very clever folks at Google published a paper on how to fine-tune this model with Dreambooth.
Using Dreambooth, you can insert any subject you want into the model. All you need are 5 to 10 images of your subject with various poses and/or backgrounds, as well as 30 minutes of your time.

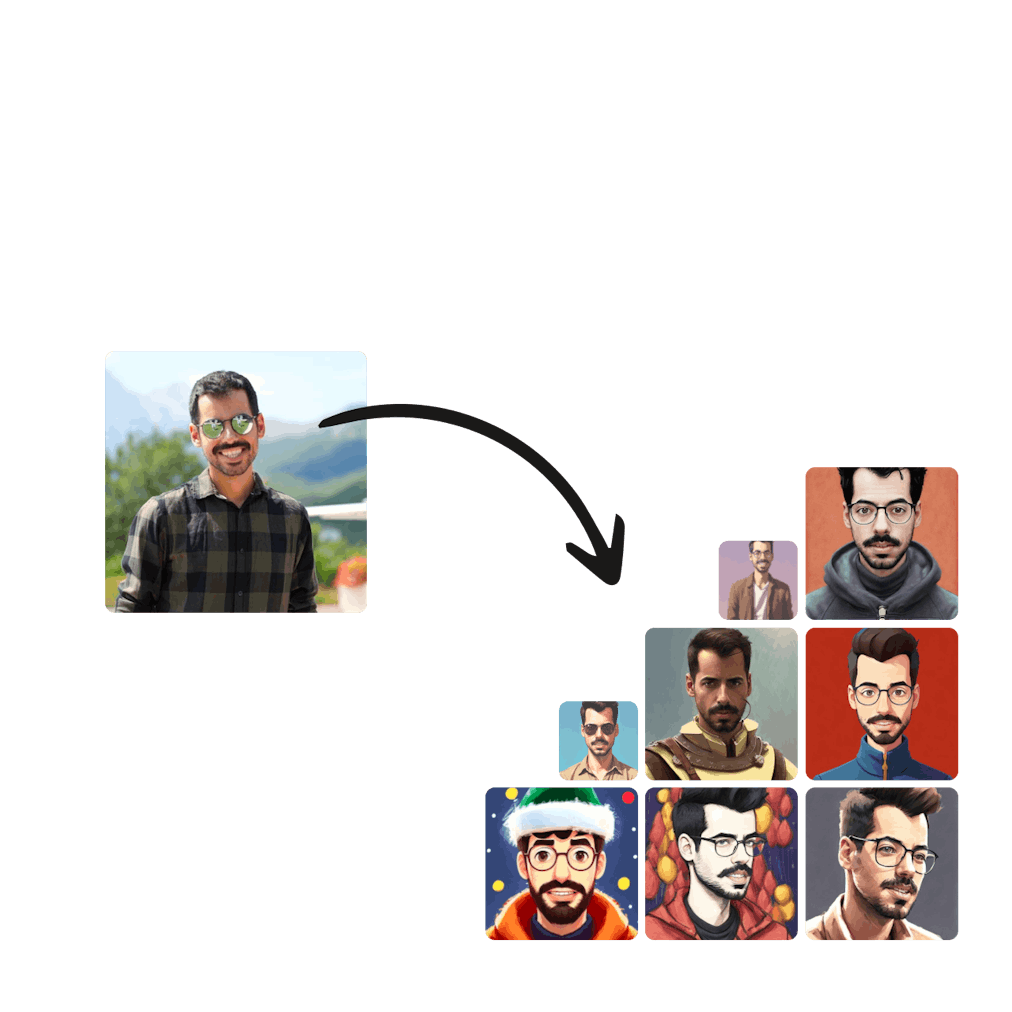
As with regular text-to-image, you can still write your prompts. However, the resulting images will resemble the input images you’ve provided.
Besides selfies, you can use a wide variety of subjects for this fine-tuning technique:

In e-commerce, great product images lead to a higher conversion rate. So, in the next few months, we expect to see many AI-based product photography applications.
Shopify’s head of product has already shown some impressive MVP’s: AI wallpapers and AI product photography.
A note on privacy
It has to be said that these fine-tuned models pose a serious privacy risk, as it allows anyone who has access to the model to output any images they want. Always make sure you're aware of this when you're using a hosted training service.
How does Stable Diffusion work?
Now, let's dig into how exactly Stable Diffusion works. Try to imagine the clouds for a moment. In your mind, you might see an image that resembles this one:


Our brain knows what clouds look like, but how does it know that? Over the years, we’ve seen our fair share of clouds. We’ve seen them in the morning, we’ve seen them in the evening, we might’ve even seen them from an airplane.
In essence, every time we’re looking at the clouds, we’re adding a mental picture to our ‘data set’ of cloud images. While doing so, we associate this image with the word cloud.


Subconsciously, our brain is constantly adding mental pictures to ‘data sets’. Thanks to these data sets, our brain can imagine things like clouds quite accurately.
Essentially, this is the way Stable Diffusion works. People at Stability AI used an extremely large data set, containing billions of images and descriptions, to train Stable Diffusion.
The training process involves adding random noise to source images. This destroys the source image until it can no longer be recognised.


The model is then trained to reverse this process and is guided with a text description. This process is called Latent Diffusion.

The resulting model can be asked to ‘imagine’ brand-new images of any concept you like, using a process called text-to-image.
Cost of hosting Stable Diffusion
Hosting Stable Diffusion can be pretty costly, since it needs lots of GPU power. The price of GPU’s in 2022 is still highly inflated due to the extreme demand in 2019-2021 for crypto mining. Although on the decline, a last-gen Nvidia 3090 GPU still costs upwards of $1.5k today.

GPU shortages are also still a thing. Cloud providers simply cannot get their hands on enough GPU’s to provide a cost-effective way of renting them. You can expect to pay about $1000 a month for an average server with 1 GPU.


What about intellectual property?
Stable Diffusion is trained on a massive data set, and includes the original work of many artists. Writing prompts such as ‘Studio Ghibli style cat’ or ‘Milth Kahl style cat’ will result in images that resemble the unique style of these artists.


This begs the question: who really owns the resulting image? As of now, we’re in a huge gray zone. Images generated with Stable Diffusion are still fully owned by the user writing the prompt. However, it is expected that this will change in the near future.
Disney, for example, is notorious for litigation when it comes to their IP, so commercialising AI images that might resemble their style is not the best idea.
What the future will bring
The rate of innovation we’re seeing in the field of AI is impressive to say the least. It's easy to lose countless hours of sleep hacking together prompts, playing with new models and fine-tuning your own.
And let's be honest: who wouldn't want a future in which you can take a selfie and see how that shirt looks on you before you buy it? If it can happen truly privately, that is.
So, although we haven’t seen their full potential yet, it's clear that models like Stable Diffusion are here to stay and adoption will happen fast.
Got a few thoughts yourself about Stable Diffusion that you'd like to share? Or want to discuss AI in general? Shoot me a message at [email protected].
By Sabatino Masala